ETL for America
By Dave Guarino
Now a few months out the intense tunnel of my Code for America fellowship year, I’ve had a bit more time and mental space to sip coffee by Lake Merritt (Oakland, CA) and reflect on issues of technology and government.
The “experience problem”
A mantra oft-repeated at Code for America is “build interfaces to government that are simple, beautiful, and easy to use.”
And that should be a core concern: bringing human-centered design and userexperience thinking to government interfaces is important work. Governments all too often tend to privilege legal accuracy over creating an accessible, enjoyable experience for constituents.
But this “experience problem” is really only one piece of the civic tech puzzle.
Data integration: a whole other can of worms
Many of the problems governments confront with technology are fundamentally about data integration: taking the disparate data sets living in a variety of locations and formats (SQL Server databases, exports from ancient ERP systems and Excel spreadsheets on people's desktops, for example) and getting them into a place and shape where they're actually usable.
Among backend software engineers, these are generically referred to as ETL problems, or extract-transform-load operations. The notion is that integrating data involves three distinct steps:
-
 Extract: getting data out of some system where it is stored and where updates are made
Extract: getting data out of some system where it is stored and where updates are made -
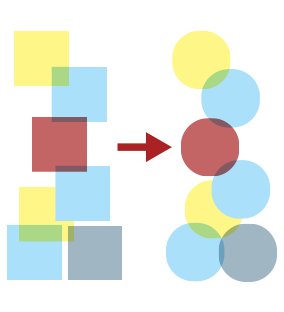 Transform: reformatting and reshaping the data in ways that make it usable
Transform: reformatting and reshaping the data in ways that make it usable -
 Load: putting the transformed data into another system, generally something where analyzing it or combining it with other data is easy for end-users
Load: putting the transformed data into another system, generally something where analyzing it or combining it with other data is easy for end-users
For example: The mayor's staff wants to put a simple dashboard on the city’s web site with building permits data. They'd like a map and some simple counts to provide residents a view of economic development in the city.
- Extract: Building permits are put into software procured in 2002 called PermitManager. IT staff write a script that nightly runs permit_manager_export.exe, which dumps the data (permits.csv) to a shared drive.
- Transform: The permit data system only contains addresses in raw text, but coordinates (latitude and longitude) are needed to put them on a map. The GIS team writes a script that every morning takes permits.csv and adds latitude and longitude columns based on the address text.
- Load: The city has an open data portal that can generate a web map for any data set on it containing latitude and longitude. Staff write a script that uploads permits-with-latitude-and-longitude.csv to the open data portal every afternoon and then embed the auto-generated web map into the city's web site.
I’ve explained ETL in this way plenty of times, and almost everyone I talk to finds it easy to understand. They just hadn’t thought about it that much. And one of the foibles here is that many government staff – particularly those at the high level – lack the basic technical language to be able to understand the structure of the ETL problem and find and evaluate the resources out there.
The fact that I can go months hearing about "open data" without a single mention of ETL is a problem. ETL is the piping in your house: it's how you open data.
ETL: a hard ^#&@ing problem
Did you notice in the example above that there are three mentions of city staff writing scripts? Wasn’t that weird? Why didn’t they use some software that does this automatically? If you search for ETL online, perhaps the most common question is whether to use an existing ETL software/framework or write custom ETL code from scratch.
This is at the core of the ETL issue: because the very problem of data integration is about bringing together disparate, heterogeneous systems, there isn’t really a clear-winner, "out-of-the-box" solution.
Couple that with the fact that governments seem to have an almost vampiric thirst for clearly market-dominating, "enterprise" solutions – there’s an old adage that "no one ever got fired for hiring IBM" – and you find yourself confronting a scary truth.
What's more, ETL is actually an intrinsically difficult technical problem. Palantir, a company which is very good with data, essentially solves the problem by throwing engineers at it. They have a fantastic analyticinfrastructure at their core, and they pay large sums of money to very smart people to do one thing: write scripts to get clients' data into that infrastructure.
What is to be done?
First a note on what not to do: do not try to buy your way out of this. There is no single solution, no single piece of software you can buy for this. Anyone who tells you otherwise is is being disingenuous. And if you pay someone external to integrate 100% of your data right now, you will be paying them again in 11 days when you change one tiny part of your system. And I bet it will be at a mark-up.
Here are a few paths forward I see as promising:
- Build internal capacity
- Hire smart, intellectually curious people who learn what they need to know to solve a problem. In fact, don’t even start by hiring. Many of these people probably already work with you but are hobbled by the inability to, say, install new software on their desktop or by cultural norms that make it unacceptable to try out new things.
- Because data integration is a difficult problem with new challenges each time it is approached, the best way to tackle it is to have motivated people who love solving new problems and give them the tools they need (whether that's training, software or a supervisorial mandate). To borrow and modify a phrase, “Let them run Linux.”
As Andrew Clay Shafer has said, “If you're not building a learning organization, you're losing to one.” And I can tell you, governments, for the most part, are not building learning organizations right now.
Explore the resources out there
I’ve started putting together a list of ETL resources for government. I'd love contributions. With just the knowledge of the acronym "ETL" and the basics of what it means, you can start to think about how you can solve your own data problems with smaller tools. (Windows Job Scheduler is analogous to In-N-Out's secret sauce.)
Because it's a generic problem not limited to government, there are many other resources out there. The data journalism folks have done a great job of writing tutorials that make existing tools accessible, and we need to work with them and follow suit.
Collaborate!
Every organization dealing with data is dealing with these problems, and governments need to work together on this. This is where open source presents invaluable process lessons for government: working collaboratively and in the open can help everyone achieve a higher level of data proficiency.
Whether it's putting your scripts on GitHub, asking and answering questions on the Open Data StackExchange or helping others on the Socrata support forums, collaboration is a key lever for this government technology problem.
Wanted: government data plumbers
In part, I'm writing this as a call to arms: all of us doing data work inside government need to start writing more publicly about our processes, hacks and tools and collaborating across boundaries.
From pure policy wonks who know just enough VBA to get stuff done to the Unix geeks whose awk knowledge strikes fear into the hearts of most sysadmins, we need to communicate more, and more publicly.
I’ve coded for America. It was hard, hard work, but incredibly fulfilling. So to my fellow plumbers I say: let’s ETL for America.
 Dave Guarino is a software developer and former analyst. He was a 2013 Fellow at Code for America. His recent work has been focused on technology that strengthens the social safety net. dave@codeforamerica.org / @allafarce
Dave Guarino is a software developer and former analyst. He was a 2013 Fellow at Code for America. His recent work has been focused on technology that strengthens the social safety net. dave@codeforamerica.org / @allafarce
Like this kinda stuff?
Consider donating to help us to continue doing this work! We also encourage reader comments via letters to the editor.